From the documentation:
HyperQueue is a tool designed to simplify execution of large workflows (task graphs) on HPC clusters. It allows you to execute a large number of tasks in a simple way, without having to manually submit jobs into batch schedulers like Slurm or PBS. You just specify what you want to compute – HyperQueue will automatically ask for computational resources and dynamically load-balance tasks across all allocated nodes and cores. HyperQueue can also work without Slurm/PBS as a general task executor.
Hyperqueue is a meta-scheduler - it consists of a server process which dynamically allocates a small-isch number slurm jobs each of which runs at least one worker process. We can then submit many potentially short running (< 10m) tasks to the server which distributes them to worker processes running as slurm jobs. This prevents overloading the slurm scheduler with very large numbers of short jobs and frequent job state queries.
Hyperqueue can be used as the backend for nextflow pipelines.
In the following example we will run a hyperqueue server instance in an sinteractive session for some simple, interactive experimentation. The server acts as a meta scheduler. We will teach it how to request larger blocks of resources from slurm and then we will use it to schedule tasks on those dynamically allocated blocks of resources (jobs running hyperqueue workers).
If you need the hyperqueue server instance to persist for longer than the limits of interactive sessions it should be run as a batch job.
For this example, allocate an interactive session
[user@biowulf]$ sinteractive --cpus-per-task=2 --mem=10g salloc.exe: Pending job allocation 46116226 salloc.exe: job 46116226 queued and waiting for resources salloc.exe: job 46116226 has been allocated resources salloc.exe: Granted job allocation 46116226 salloc.exe: Waiting for resource configuration salloc.exe: Nodes cn3144 are ready for job
and start a hyperqueue server in the background.
[user@cn3144 ~]$ module load hyperqueue [user@cn3144 ~]$ export HQ_SERVER_DIR=/data/$USER/.hq-server [user@cn3144 ~]$ # start a server in the background [user@cn3144 ~]$ ( hq server start --journal ./journal &> server.log & ) [user@cn3144 ~]$ hq server info +-------------+-------------------------+ | Server UID | f2C5h9 | | Client host | cn3144 | | Client port | 33617 | | Worker host | cn3144 | | Worker port | 36171 | | Version | v0.19.0 | | Pid | 1342848 | | Start date | 2024-10-10 12:56:55 UTC | +-------------+-------------------------+
Now we need to tell the server how to allocate workers which will be running our hyperque jobs/tasks. We will use automatic allocation by allowing the server to dynamically submit slurm jobs depending on how many jobs are submitted to hyperqueue. Each of the slurm jobs submitted by hyperqueue will be running a worker process to execute hyperqueue jobs. Each worker can execute multiple hyperqueue jobs depending on the resources requested by each hyperqueue job relative to the resources available to the worker. Hyperqueue workers will automatically detect the available cores/cpus and GPUs but as of version 0.19.0 does not correctly detect allocated memory. We therefore specify the memory in MiB explicitly.
Definition of resources can be fairly sophisticated. See the official documentation for more details.
[user@cn3144 ~]$ hq alloc add slurm --time-limit 4h --worker-time-limit 3:50:00 \
-n work --max-worker-count 4 --resource "mem=sum($((12 * 1024)))" -- \
--partition=quick --mem=12g --cpus-per-task=6
2024-10-10T13:42:28Z INFO A trial allocation was submitted successfully. It was immediately canceled to avoid wasting resources.
2024-10-10T13:42:28Z INFO Allocation queue 1 successfully created
[user@cn3144 ~]$ hq alloc list --output-mode json
[
{
"additional_args": [
"--partition=quick",
"--mem=12g",
"--cpus-per-task=6"
],
"backlog": 1,
"id": 1,
"manager": "Slurm",
"max_worker_count": 4,
"name": "work",
"state": "Running",
"timelimit": 14400.0,
"worker_args": [
"--resource",
"\"mem=sum(12288)\"",
"--on-server-lost",
"\"finish-running\"",
"--time-limit",
"\"3h 50m\""
],
"workers_per_alloc": 1
}
]
At this point, hyperqueue will not have started a worker yet. Once we submit
a hyperqueue job it will start to allocate workers with sbatch.
A hyperqueue job is a collection of tasks - either a single task for simple jobs or a task array similar to slurm job arrays/swarms.
[user@cn3144 ~]$ hq submit --cpus=1 --resource 'mem=100' --time-limit=1m hostname
Job submitted successfully, job ID: 1
[user@cn3144 ~]$ squeue -u $USER
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
46116226 interacti sinterac user R 1:23:19 1 cn0001
46116227 quick work-1 user PD 0:00 1 (None)
[user@cn3144 ~]$ hq job info 1
+----------------------+---------------------------------------------------------+
| ID | 1 |
| Name | hostname |
| State | FINISHED |
| Tasks | 1; Ids: 0 |
| Workers | cn2068 |
| Resources | cpus: 1 compact |
| | mem: 100 compact |
| Priority | 0 |
| Command | hostname |
| Stdout | /path/to/current/working/dir/job-1/%{TASK_ID}.stdout |
| Stderr | /path/to/current/working/dir/job-1/%{TASK_ID}.stderr |
| Environment | |
| Working directory | /path/to/current/working/dirtow |
| Task time limit | 1m |
| Crash limit | 5 |
| Submission date | 2024-10-10 14:07:35 UTC |
| Submission directory | /path/to/current/working/dir |
| Makespan | 31s 372ms |
+----------------------+---------------------------------------------------------+
[user@cn3144 ~]$ cat job-1/0.stdout
cn2068
We'll run an example stochastic pi estimation program where the
$HQ_TASK_ID is used to seed the random number generator. Note that
we use bash -c '...' to prevent premature epansion of the task id
variable at submission time.
[user@cn3144 ~]$ hq submit --cpus=2 --resource 'mem=100' --time-limit=3m --progress --array 1-20 \
bash -c 'pi 200 2 $HQ_TASK_ID'
Job submitted successfully, job ID: 2
2024-10-10T19:33:15Z INFO Waiting for 1 job with 3 tasks
[........................................] 0/1 jobs, 0/20 tasks
[user@cn3144 ~]$ cat job-2/*.stdout
thread 1: pi = 3.141592939999999778422079543816 [200M iterations]
thread 0: pi = 3.141515019999999935862433630973 [200M iterations]
overall pi est = 3.141553979999999857142256587395
pi real= 3.141592653589793115997963468544
seed = 1
[...snip...]
In this case it's ok to have very short jobs since (a) we are running a single executable which does not stress the filesystem during repeated startups and (b) we are runnign realtively few tasks. In the case of running massive numbers of short interpreted jobs the file systems may still get stressed by the I/O intensive task of starting a python or R interpreter many times over. If your jobs fit this pattern please contact staff to discuss other approaches.
Here is an example of doing the same thing as above but with single hyperqueue jobs.
[user@cn3144 ~]$ for i in {1..100} ; do
hq submit --cpus=2 --resource 'mem=100' --time-limit=3m pi 200 2 $i
done
Job submitted successfully, job ID: 3
Job submitted successfully, job ID: 4
Job submitted successfully, job ID: 5
Job submitted successfully, job ID: 6
Job submitted successfully, job ID: 7
[...snip...]
[user@cn3144 ~]$ hq jobs list --filter running
+----+------+---------+-------+
| ID | Name | State | Tasks |
+----+------+---------+-------+
| 90 | pi | RUNNING | 1 |
| 91 | pi | RUNNING | 1 |
| 92 | pi | RUNNING | 1 |
+----+------+---------+-------+
There are 102 jobs in total. Use `--all` to display all jobs.
[user@cn3144 ~]$ squeue -u $USER
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
49138845 interacti sinterac user R 3:48:38 1 cn4272
49172634 quick work-5 user PD 0:00 1 (None) <--- hyperqueue jobs
49172479 quick work-4 user R 1:58 1 cn4359 <--/
[user@cn3144 ~]$ jobload
JOBID TIME NODES CPUS THREADS LOAD MEMORY
Elapsed / Wall Alloc Active Used / Alloc
i 49138845 0-03:48:15 / 0-08:00:00 cn4272 2 0 0% 0.0 / 10.0 GB
49172479 0-00:01:35 / 0-04:00:00 cn4359 6 6 100% 0.0 / 12.0 GB
Note that hyperqueue will scale the number of worker processes up as needed and will terminate workers after a configurable idle period.
One additional problem when running many short jobs is the generation of stdout and stderr files for each hyperqueue job which could result in the generation of many files. One solution for this, if you only need those files in case of failure, is to automatically clean up files for jobs that finish successfully. Since any job-specific directories are not cleaned up it makes the most sense when putting all the job files into a single directory. For example:
[user@cn3144 ~]$ hq submit --cpus=2 --resource 'mem=100' \
--stdout="%{CWD}/logs/job-%{JOB_ID}.%{TASK_ID}.o:rm-if-finished" \
--stderr="%{CWD}/logs/job-%{JOB_ID}.%{TASK_ID}.e:rm-if-finished" \
--time-limit=3m pi 200 2 10
Another solution to the problem of generating too many output files is
to stream the stdout and stderr into a single file. For this example let's
simulate a large swarm with something that looks somewhat like a swarmfile. We'll
call it a horde. There is one major difference though: The lines in the file
will be passed to the command provided during submission as the value of the
$HQ_ENTRY variable. You can still execute it like a command by
passing the entry to bash -c '$HQ_ENTRY':
[user@cn3144 ~]$ for i in {1..1000} ; do echo "pi 200 2 $i"; done > hordefile
[user@cn3144 ~]$ head -3 hordefile
pi 200 2 1
pi 200 2 2
pi 200 2 3
[user@cn3144 ~]$ mkdir -p logs
[user@cn3144 ~]$ hq submit --each-line hordefile --cpus=2 --resource 'mem=100' --time-limit=3m --stream=logs bash -c '$HQ_ENTRY'
[user@cn3144 ~]$ hq job list
+-----+------+---------+-------+
| ID | Name | State | Tasks |
+-----+------+---------+-------+
| 107 | bash | WAITING | 1000 |
+-----+------+---------+-------+
There are 107 jobs in total. Use `--all` to display all jobs.
[user@cn3144 ~]$ hq job progress 107
2025-02-26T20:38:05Z INFO Waiting for 1 job with 1000 tasks
[##......................................] 0/1 jobs, 15/1000 tasks (3 RUNNING, 15 FINISHED)
Ctrl-C
[user@cn3144 ~]$ jobload
JOBID TIME NODES CPUS THREADS LOAD MEMORY
Elapsed / Wall Alloc Active Used / Alloc
i 49138845 0-05:41:26 / 0-08:00:00 cn4272 2 0 0% 0.0 / 10.0 GB
49186281 0-00:08:57 / 0-04:00:00 cn4368 6 6 100% 0.0 / 12.0 GB
49186396 0-00:08:08 / 0-04:00:00 cn4350 6 6 100% 0.0 / 12.0 GB
49186776 0-00:05:37 / 0-04:00:00 cn4350 6 6 100% 0.0 / 12.0 GB
49186965 0-00:04:26 / 0-04:00:00 cn4340 6 6 100% 0.0 / 12.0 GB
[user@cn3144 ~]$ ls -lh logs
total 260K
-rw-r--r--. 1 user staff 35K Feb 26 15:48 F5TVTZKC0rYD.hqs
-rw-r--r--. 1 user staff 76K Feb 26 15:48 Pmm3QfPqt2Fg.hqs
-rw-r--r--. 1 user staff 74K Feb 26 15:48 QJvO8wH1nTWN.hqs
-rw-r--r--. 1 user staff 53K Feb 26 15:48 vGArVdOHo77r.hqs
[user@cn3144 ~]$ hq output-log logs summary
+-------------------------------+------------------+
| Path | logs |
| Files | 4 |
| Jobs | 1 |
| Tasks | 1000 |
| Opened streams | 0 |
| Stdout/stderr size | 250.87 KiB / 0 B |
| Superseded streams | 0 |
| Superseded stdout/stderr size | 0 B / 0 B |
+-------------------------------+------------------+
[user@cn3144 ~]$ hq output-log logs cat --task 10 107 stdout
thread 1: pi = 3.141754099999999993997334968299 [200M iterations]
thread 0: pi = 3.141753959999999956664851197274 [200M iterations]
overall pi est = 3.141754029999999975331093082787
pi real= 3.141592653589793115997963468544
seed = 11
[user@cn3144 ~]$ hq submit --cpus=2 --resource 'mem=100' --time-limit=3m pi 200 2 10 Job submitted successfully, job ID: 103 [user@cn3144 ~]$ hq job list +-----+------+---------+-------+ | ID | Name | State | Tasks | +-----+------+---------+-------+ | 103 | pi | WAITING | 1 | +-----+------+---------+-------+ There are 103 jobs in total. Use `--all` to display all jobs. [user@cn3144 ~]$ hq job cancel 103 2025-02-26T20:05:24Z INFO Job 103 canceled (1 tasks canceled, 0 tasks already finished)
More complicated pipelines with dependencies and detailed properties can be defined in jobfiles in toml format. For example:
[user@cn3144 ~]$ cat > pipeline.toml <<__EOF__
name = "my-wonderful-pipeline-nobel-here-i-come"
stream = "logs"
max_fails = 1
[[task]]
id = 1
command = ["pi", "200", "2", "1"]
[[task.request]]
resources = { "cpus" = 2, "mem" = 100 }
time_request = "3m"
[[task]]
id = 3
command = ["pi", "200", "2", "11"]
[[task.request]]
resources = { "cpus" = 2, "mem" = 100 }
time_request = "3m"
[[task]]
id = 5
command = ["pi", "200", "2", "111"]
deps = [1, 3]
[[task.request]]
resources = { "cpus" = 2, "mem" = 100 }
time_request = "3m"
__EOF__
[user@cn3144 ~]$ hq job submit-file pipeline.toml
[user@cn3144 ~]$ hq job list
+-----+-----------------------------------------+---------+-------+
| ID | Name | State | Tasks |
+-----+-----------------------------------------+---------+-------+
| 109 | my-wonderful-pipeline-nobel-here-i-come | WAITING | 3 |
+-----+-----------------------------------------+---------+-------+
There are 109 jobs in total. Use `--all` to display all jobs.
In addition to the command line tool, hyperqueue also provides a python api.
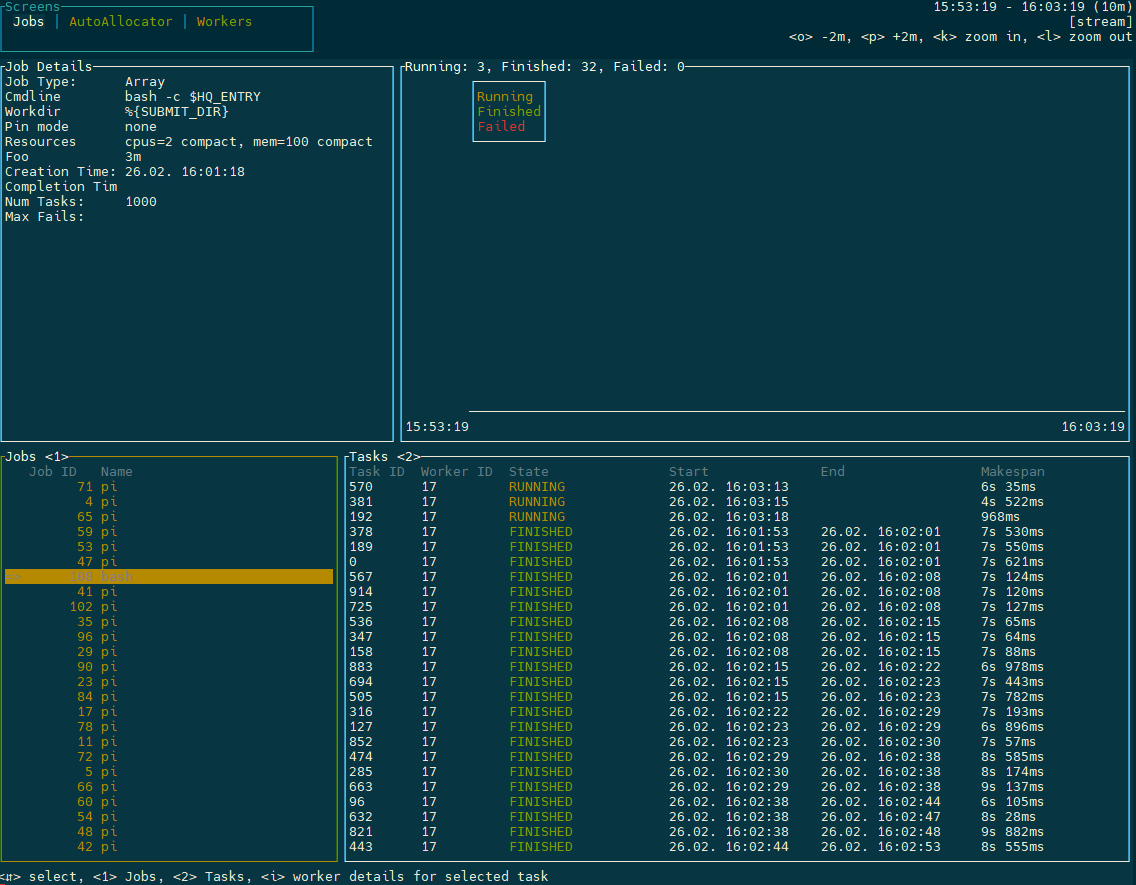
hyperqueue includes an experimental dashboard
[user@cn3144 ~]$ hq dashboard
Stop the server and exit the session
[user@cn3144 ~]$ hq server stop [user@cn3144 ~]$ exit salloc.exe: Relinquishing job allocation 46116226 [user@biowulf ~]$
If a server needs to be resum-able start it with the --journal=/path/to/journal
option as we did in the example above. This is also neccessary to use the dashboard. For more details see
the official docs
hyperqueue uses a server dir to store state information. This directory has
to be located on a shared file system and defaults to
$HOME/.hq-server. In the example above we set the
$HQ_SERVER_DIR environment variable to use a non-default location.
A separate server dir is required for each concurrent hyperqueue
server which can be achieved by setting the environment variable above or
adding the --server-dir option to the various hq
commands.
The following batch script starts an hq server, adds an allocation queue and then runs the commands in a "hordefile":
#!/bin/bash
die() {
printf "ERROR: %s\n" "$*" >&2
exit 1
}
cleanup() {
printf "Cleanup\n"
hq server stop &> /dev/null ||:
rm -rf $HQ_SERVER_DIR
}
module load hyperqueue || die "Unable to load hyperqueue module"
hordefile="${1:-none}"
[[ -e "${hordefile}" ]] || die "missing hordefile"
export HQ_SERVER_DIR="/data/$USER/.hq-server-${SLURM_JOB_ID}"
mkdir -p "${HQ_SERVER_DIR}"
trap 'cleanup' EXIT
( hq server start --journal ./journal-${SLURM_JOB_ID} &> server-${SLURM_JOB_ID}.log & )
sleep 10
if hq server info &> /dev/null
then
printf "hyperqueue server started successfully\n"
hq alloc add slurm \
--time-limit 4h \
--worker-time-limit 3:50:00 \
-n work \
--max-worker-count 4 \
--resource "mem=sum($((12 * 1024)))" -- \
--partition=quick --mem=12g --cpus-per-task=6 || die "could not add allocation to server"
mkdir -p hq-logs-${SLURM_JOB_ID}
hq submit \
--each-line "${hordefile}" \
--cpus=2 \
--resource 'mem=100' \
--time-limit=3m \
--stream=hq-logs-${SLURM_JOB_ID} \
--progress \
bash -c '$HQ_ENTRY'
exit
hq server stop
else
die "hyperqueue server failed to start"
fi
Submit this job using the Slurm sbatch command.
sbatch --cpus-per-task=2 --mem=6g --time=120 hyperqueue.sh hordefile