Important: Please read the webpage Making efficient use of Biowulf's Multinode Partition before running large parallel jobs.
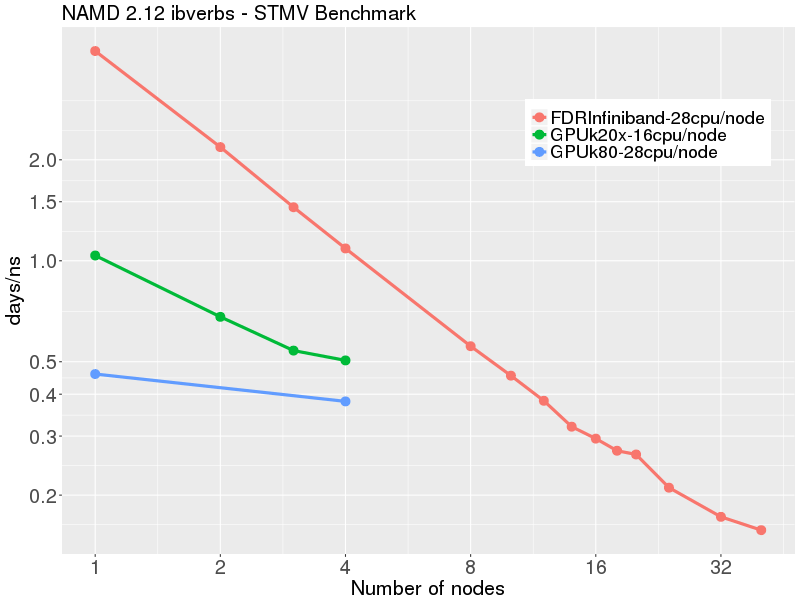
STMV benchmark, 1,066,628 atoms, periodic, PME (available from here)
The Infiniband CPU benchmarks were performed with NAMD 2.12, Linux-x86_64-ibverbs , downloaded from here.
GPU benchmarks were performed with NAMD 2.12, Linux-x86_64-ibverbs-smp-CUDA downloaded from here.
The data shows that using nodes with Nvidia K80 GPUs provides a substantial speedup over nodes with K20x GPUs. Note that each k80 node has 2 GPUs cards, each of which has 2 GPUs (total 4 GPU devices per K80 node). Performance on a single K80 node with 4 GPUs (~0.45 days/ns) was about the same as 12 FDR Infiniband nodes. The scaling on the GPU nodes demonstrates that it is little advantage to using more than a single K80 node, as parallel efficiency drops dramatically beyond a single node.
| # nodes | CPUs only 28 x 2.3 GHz Intel E5-2695v3 56 Gb/s FDR Infiniband (1.11:1) | 2 x GPU k20x CPU 16 x 2.6 GHz Intel E5-2650v2 56 Gb/s FDR Infiniband (1.11:1) | 4 x GPU k80 (2 k80 cards) CPU 28 x 2.3 GHz Intel E5-2695v3 56 Gb/s FDR Infiniband (1.11:1) days/ns | Efficiency % | days/ns | Efficiency % | days/ns | Efficiency %
| 1 | 4.22 | 100 % | 1.03681 | 100 % | 0.451188 | 100 %
| 2 | 2.18 | 97 % | 0.680407 | 32 % |
| 4 | 1.09 | 97 % | 0.504489 | 12 % | 0.411467 | 23 %
| 8 | 0.55 | 95 % | | |
| 16 | 0.29 | 89 % |
| 32 | 0.17 | 77 % | |
| 40 | 0.15 | 67 % |
| | |||||||||||||
STMV benchmark on a single K80 node, with NAMD 2.12 ibverbs. Runs used all 28 physical cores, and 1, 2 or 4 GPU devices on the node.
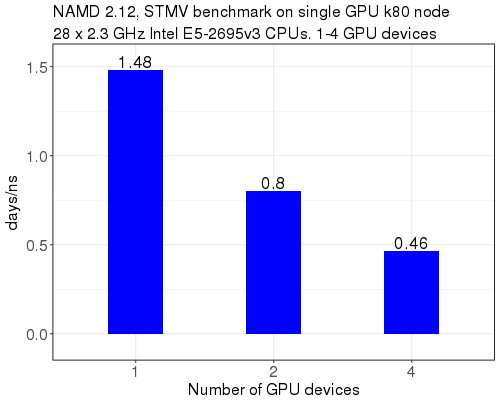
This benchmark shows that using all 4 GPUs on a k80 node (0.46 days/ns) produces ~3.2x the performance of using only 1 GPU (1.48 days/ns). Ideally, we would see 4 GPU devices give ~4x the performance of a single GPU device. However, given the 3.2x scaling, it is worth allocating an entire K80 node and utilizing all 4 GPU devices.
The Infiniband CPU benchmarks were performed with NAMD 2.12, Linux-x86_64-ibverbs , downloaded from here.
GPU benchmarks were performed with NAMD 2.12, Linux-x86_64-ibverbs-smp-CUDA downloaded from here.
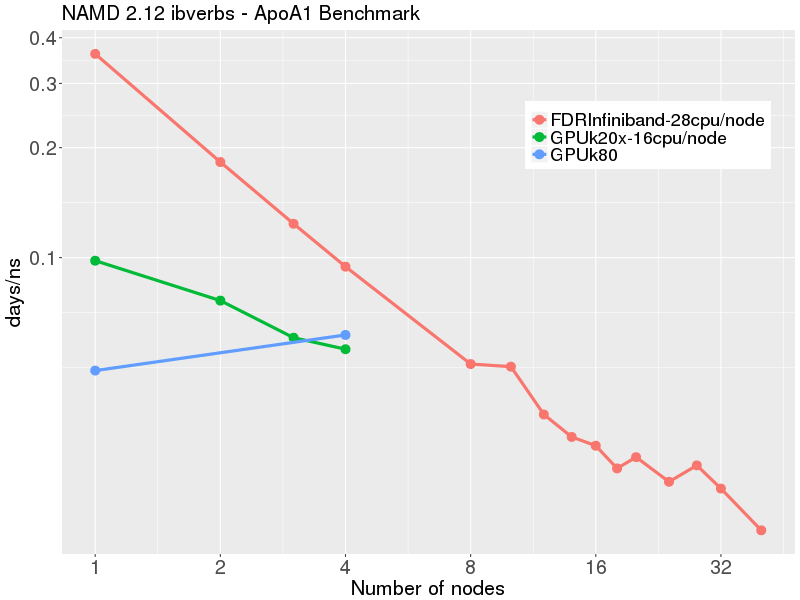
The data shows that for a small molecular system such as Apoa1, efficiency drops off at after 8 nodes (8*28 = 224 cores). Running on a K20x GPU node (2 GPUs, 32 physical cores) gives about the same performance as 4 FDR IB nodes (112 physical cores). Running on a GPU K80 node (2 k80 cards, i.e. 4 GPU devices + 28 physical cores) gives about the same performance as on 6 FDR IB nodes (168 physical cores). For this small molecular system, it is inefficient to run on more than 1 GPU node or 8-12 FDR IB nodes.
| # nodes | CPUs only 28 x 2.3 GHz Intel E5-2695v3 56 Gb/s FDR Infiniband (1.11:1) | 2 x GPU k20x CPU 16 x 2.6 GHz Intel E5-2650v2 56 Gb/s FDR Infiniband (1.11:1) | 4 x GPU k80 (2 k80 cards) CPU 28 x 2.3 GHz Intel E5-2695v3 56 Gb/s FDR Infiniband (1.11:1) days/ns | Efficiency % | days/ns | Efficiency % | days/ns | Efficiency %
| 1 | 0.36 | 99 % | 0.098092 | 0.0703323
| 2 | 0.18 | 99 %
| 4 | 0.09 | 96 %
| 8 | 0.05 | 88 %
| 16 | 0.03 | 74 %
| 32 | 0.02 | 48 %
| 40 | 0.018 | 50 %
| | ||||
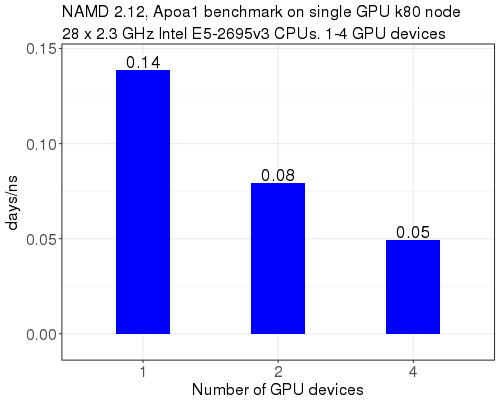
This benchmark shows that using all 4 GPUs on a k80 (0.05 days/ns) is ~2.8x the performance of using only 1 GPU (0.14 days/ns). For this small molecular system, using 1 or 2 GPU devices on a K80 node is appropriate.