There are several options for disk storage on the NIH HPC; please review this section carefully to decide where to place your data. Contact the NIH HPC systems staff if you have any questions.
Except where noted, there are no quotas, time limits or other restrictions placed on the use of space on the NIH HPC, but please use the space responsibly; even hundreds of terabytes won't last forever if files are never deleted. Disk space on the NIH HPC should never be used as archival storage.
Users who require more than the default disk storage quota should fill out the online storage request form.
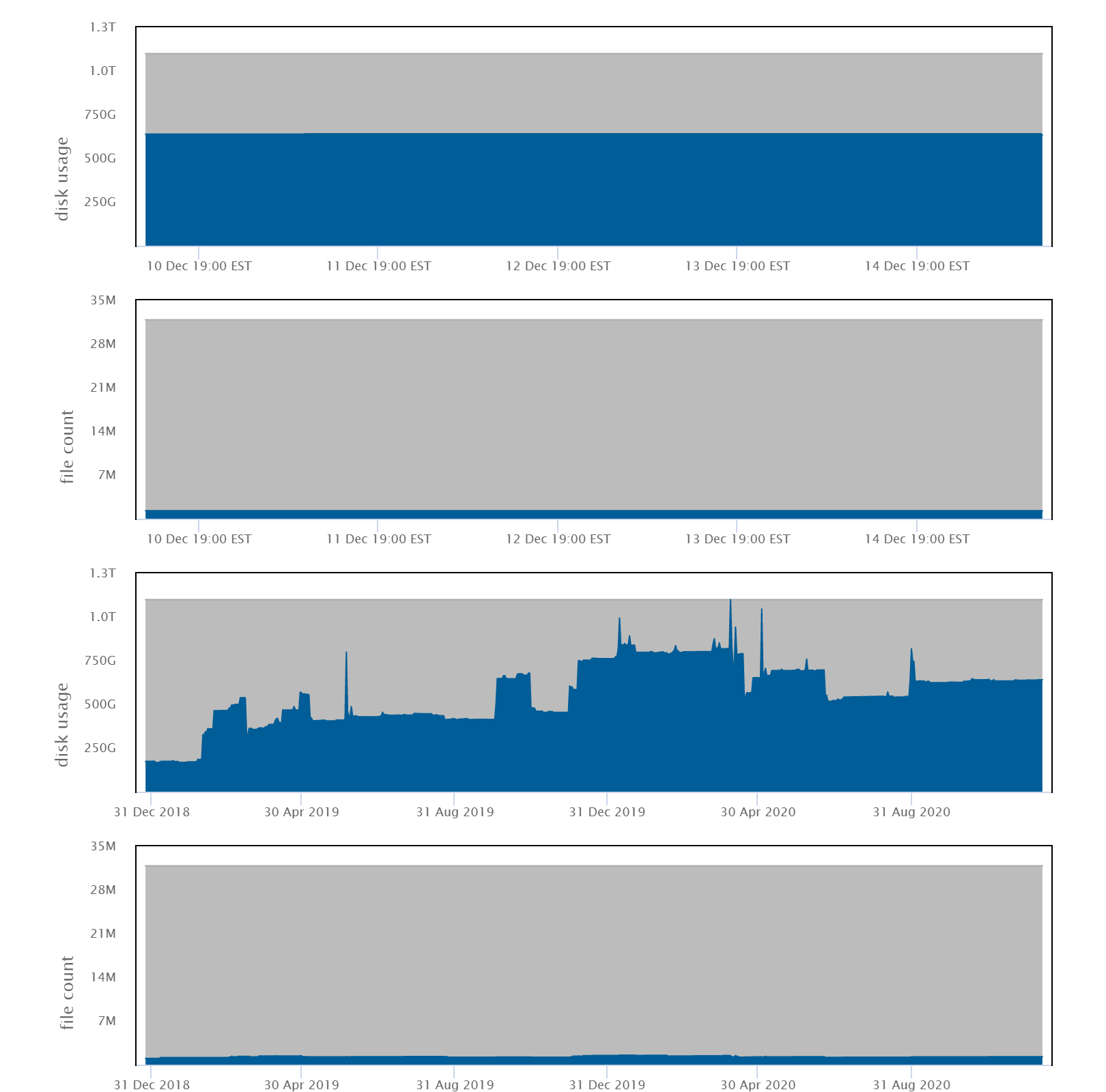
NOTE: Historical traces of disk usage and file counts are available through the User Dashboard.
| Location | Creation | Backups | Space | Available from | |
| /home | network (NFS) | with Biowulf/Helix account | yes | 16 GB quota | Biowulf login node Biowulf compute nodes Helix |
| /lscratch (nodes) | local | created by user job | no | up to ~3,200 GB as requested by job | Biowulf compute nodes only |
| /scratch | network (NFS) | created by user | no | 100 TB shared | Biowulf login node Helix |
| /data | network (GPFS/NFS) | with Biowulf/Helix account | no | 100 GB default quota | Biowulf login node Biowulf compute nodes Helix |
Each user has a home directory called /home/username which is accessible from every HPC system. The /home area has a quota of 16 GB which cannot be increased. It is commonly used for config files (aka dotfiles), code, nodes, executables, state files, and caches.
Each Biowulf node has a directly attached disk containing a /lscratch filesystem. Note that this space is not backed up, and thus, users should use it only as temporary space while running a job. Once the job exits, you will no longer have access to /lscratch on the node.
To use /lscratch, see Using Local Disk in the Biowulf User Guide.
Please use /lscratch (on compute nodes) or /scratch (on the Biowulf login node or Helix) instead of /tmp for storage of temporary files.
There is a shared /scratch area that is accessible from Helix and the Biowulf login node. /scratch is a large, low performance area meant for the storage of temporary files.
Files in /scratch are automatically deleted 10 days after last access.
Each user can store up to a maximum of 10 TB in /scratch. However, 10 TB of space is not guaranteed to be available at any particular time.
If the /scratch area is more than 80% full, the HPC staff will delete files as needed, even if they are less than 10 days old.
These are filesystems mounted over NFS or GPFS from one of the following, all of which are configured for high availability: an all-flash VAST storage system, six DataDirect Networks SFA12K storage systems with eight fileservers each, a DataDirect Networks SFA18K storage system with eight fileservers, and two NetApp FAS9000 controllers. This storage offers high performance NFS/GPFS access, and is exported to Biowulf over a dedicated high-speed network. /data is accessible from all computational nodes as well as Biowulf and Helix, and will be the storage of choice for most users to store their large datasets. Biowulf users are assigned an initial quota of 100 GB on /data; please fill out the online form if you need to increase your quota.
Note: your /data directory is actually physically located on filesystems named /vf, /gs# or /spin1. /data/username will always point to the correct location of your data directory. In your batch scripts or on the command line, ALWAYS refer to your data directory as /data/username because your data directory might be moved to balance the loads, or when filesystems are added or retired. In other words, use /data/username rather than (for example) /gs12/users/username in your scripts.
Snapshots are available that allow users to recover files that have been inadvertently deleted. Note that access to the snapshots differs for the three types of storage systems. For more information on backups and snapshots, please refer to the File Backups webpage.
For the small minority of HPC users with a data directory located on the /spin1 storage area, it is possible that the size of snapshots in your data directory may cause a user to have less available storage space than you expect.
Each data directory on /spin1 has its own snapshot space that is separate from a user's regular file or data space. However, if you delete a lot of data within a short period of time (a week or less), it is possible that the snapshot space for that data directory can be exceeded. When this occurs, regular file space (allocated quota space) will be used as additional snapshot space. Unfortunately there is no way for you to either determine that this is the situation, or to actually delete snapshots. If you delete a large amount of data and do not see the expected increase in available space, you should contact the HPC staff for assistance. This situation will NOT occur for data directories located on the VAST or GPFS filesystems.
Note: Small files (< 128 KB) will give rise to differences between disk usage as shown by the
checkquotacommand, theducommand, and a sum of individual file sizes as shown by thelscommand. This is due to the way files are written to disks within the GPFS and VAST storage systems. The disk usage shown bycheckquotaandducan be significantly larger than what is expected from a sum of file sizes.
Information on methods for sharing data with collaborators both inside and outside NIH can be found on our sharing data webpage,
Use the checkquota command to determine how much disk space you are using:
$ checkquota Mount Used Quota Percent Files Limit Percent /data: 5.2 GB 500.0 GB 1.04% 23 31457280 0.00% /data(SharedDir): 4.1 TB 10.5 TB 38.67% 103357 31876696 0.32% /home: 10.3 GB 16.0 GB 64.62% 73 n/a 0.00% ObjectStore Vaults vault: 5.7 MB 465.7 GB 0.00% n/a n/a 0.00%
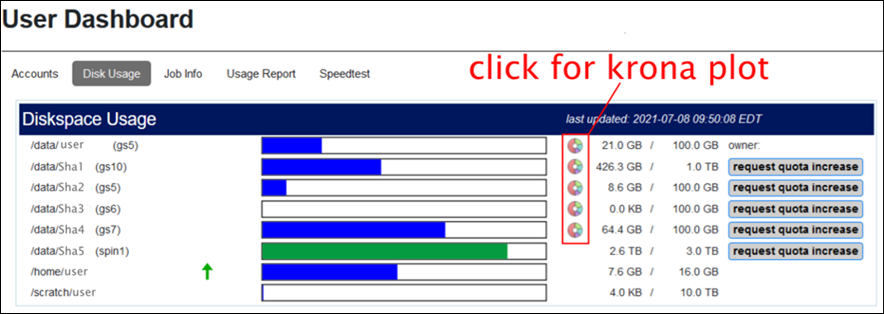
You can also see your usage history in the User Dashboard, under the Disk Usage tab:
Biowulf disk storage is intended for active data and cannot be used for longterm archiving. To help users and groups manage their data on Biowulf, the HPC User Dashboard provides Krona-based visualizations of their data directories that show the distribution and age of data. These interactive hierarchical maps of data and shared directories will assist users in finding unused or infrequently accessed old data that could be archived. They also provide a simple overview of the storage distribution in individual or shared data directories, and will help users easily identify large subdirectory trees.
Click on the circular icon next to each /data area in the dashboard to see its krona plot.
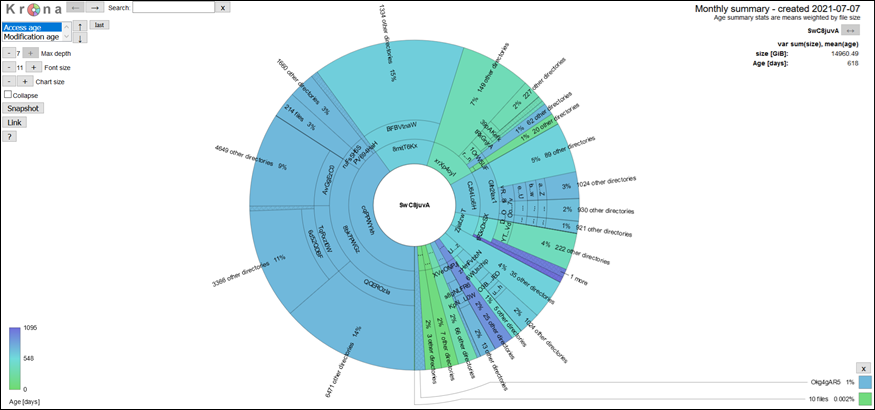
Below is a sample krona plot of a data directory. The size of the slices represents the total size of a directory and the color indicates the size-weighted mean age (access or modification) of the files in the directory. The plots on the dashboard are browsable with summary statistics shown in the top right corner.
There is a special tool called dust (requires module load extrautils) that can discover the largest sources of disk usage in a terminal session:
$ module load extrautils $ dust /home/$USER 4.1G ┌── 14466f9d658bf4a79f96c3f3f22759707c291cac4e62fea625e80c7d32169991 │ ░░░░░░░░░░░░░░██████████████ │ 45% 4.1G ┌─┴ blobs │ ░░░░░░░░░░░░░░██████████████ │ 45% 4.1G ┌─┴ models--TheBloke--Mistral-7B-Instruct-v0.1-GGUF │ ░░░░░░░░░░░░░░██████████████ │ 45% 4.1G ┌─┴ hub │ ░░░░░░░░░░░░░░██████████████ │ 45% 4.1G ┌─┴ huggingface │ ░░░░░░░░░░░░░░██████████████ │ 45% 529M │ ┌── 3 │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓▓██ │ 6% 400M │ │ ┌── 5 │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓▓██ │ 4% 400M │ │ ┌─┴ 8 │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓▓██ │ 4% 559M │ ├─┴ b │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓▓██ │ 6% 642M │ ├── 5 │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓███ │ 7% 674M │ │ ┌── f8d5980fe9337a0ff0bcb7fdd1683027b2753ba487bcab87f3d1151c.body│ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓███ │ 7% 674M │ │ ┌─┴ 9 │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓███ │ 7% 674M │ │ ┌─┴ 5 │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓███ │ 7% 674M │ │ ┌─┴ d │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓███ │ 7% 674M │ │ ┌─┴ 8 │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓███ │ 7% 670M │ │ │ ┌── f5b8549dc0968dde80eff01f860b55e10e42edd86c6bdf34d543c919.body│ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓███ │ 7% 670M │ │ │ ┌─┴ 5 │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓███ │ 7% 670M │ │ │ ┌─┴ 8 │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓███ │ 7% 670M │ │ │ ┌─┴ b │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓███ │ 7% 694M │ │ ├─┴ 5 │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓███ │ 7% 1.5G │ ├─┴ f │ ░░░░░░░░░░░░░▓▓▓▓▓▓▓▓▓▓█████ │ 17% 4.5G │ ┌─┴ http-v2 │ ░░░░░░░░░░░░░███████████████ │ 50% 4.5G ├─┴ pip │ ░░░░░░░░░░░░░███████████████ │ 50% 8.6G ┌─┴ .cache │ ████████████████████████████ │ 95% 9.1G ┌─┴ user │█████████████████████████████ │ 100%
BAD GOOD Submitting a swarm without knowing how much data it will generate Run a single job, sum up the output and tmp files, and figure out if you have enough space before submitting the swarm Directory with 1 million files Directories with < 5,000 files 100 jobs all reading the same 50 GB file over and over from /data/$USER/ Use /lscratch instead, copy the file there, and have each job access the file on local disk 100 jobs all writing and deleting large numbers of small temporary files Use /lscratch instead, have all tmp files written to local disk Each collaborator having a copy of data on Biowulf Ask for a shared area and keep shared files there to minimize duplication Use Biowulf storage for archiving Move unused or old data back to you local system